Ce texte ne représente pas l'opinion de mes employeurs successifs, surtout pas le premier. De plus, je n'ai pas assisté en personne ŕ tous les événements décrits ici, donc une partie est le fruit de suppositions. Elles seront présentées comme telles en temps utile. D'autre part, pour des raisons que vous comprendrez sans peine, j'ai supprimé certains noms propres de ce texte, il ne reste plus que quelques noms de constructeurs d'ordinateurs et de systčmes d'exploitation.
Ce texte ne parle pas directement de Perl. Son but est de vous inciter ŕ vérifier la couverture de code de vos programmes et de vos modules, avec par exemple le module Devel::Cover.
Il n'est pas toujours possible d'assurer une couverture de code ŕ 100% et, męme si la couverture totale est réalisée, cela ne veut pas dire qu'il n'existe pas de bug. Paul Johnson le rappelle dans la documentation de son module. Cela dit, essayez d'avoir la couverture la plus large possible, cela peut vous éviter quelques désagréments, voire quelques catastrophes.
Voici un exemple de catastrophe qui aurait pu ętre évitée par une meilleure couverture de code. Cet exemple n'est pas en Perl, donc il faut que je vous indique le cadre historique et technique. C'est d'ailleurs pour cela que cet exposé ne pouvait pas ętre une communication-éclair de 5 minutes.
"La Boîte" a été créée ŕ la fin des années 1960. Dčs le début des années 1970, La Boîte s'oriente vers le développement informatique et devient une SSCI. Son activité est essentiellement basée sur COBOL, mais avec quelques exceptions. Ŕ une date que je ne connais pas, la Boîte crée "l'AGL", qui permet de simplifier la programmation COBOL.
1985, je commence ŕ travailler dans La Boîte, l'AGL étant ŕ la version 7.1
1986, La Boîte développe la version 7.2 de l'AGL puis commence ŕ la diffuser pour les machines IBM-CICS. Début 1987, le client chez qui je travaille installe cette version.
Mi-1987, je change de client, je reviens ŕ l'AGL 7.1 sur Sperry-Unisys.
Janvier 1988 : un mois paisible pour moi et mes collčgues directs, mais pas pour tout le monde.
1993, La Boîte devient une filiale d'une Grosse Boîte. Puis en 1998 ou 1999, La Boîte disparaît au sein de la Grosse Boîte.
L'AGL est basé sur une base de données contenant tout ce qu'il faut pour générer des programmes, ainsi que pour saisir des textes pour les spécifications, les manuels utilisateur, la documentation, et ainsi de suite. Pour des programmes, il y a plusieurs niveaux de description. Il y a une table qui contient des lignes de code sous une forme trčs proche du langage COBOL, il y a d'autres tables permettant de décrire une grille d'écran ou une structure de base de données, des notions de plus haut niveau.
Côté programmes, l'AGL contient deux grandes parties. La premičre est une série de programmes pour mettre ŕ jour la base de données en interactif. La deuxičme partie est une série de programmes générant des sources COBOL. Ces programmes fonctionnent en mode batch. L'utilisateur n'intervient que pour lancer le programme puis ŕ la fin pour lire le compte-rendu.
Dans le schéma ci-dessous, le compilateur n'est pas fourni dans l'AGL, il est fourni par le constructeur de la machine : IBM, BULL, Sperry-Unisys, etc. D'autre part, les fichiers marqués SRC contiennent le source COBOL des programmes. En principe, ce sont des fichiers temporaires. S'il y a une erreur ŕ la compilation, c'est dans la base de données qu'il faut intervenir pour corriger l'erreur.
___
( ) Squelette
_____ ___ (___) de programme
|( )| (___) | _____ _____
|( )| -------- | | -->------- ( ) --------------- ( )
------| <-->| MAJ |<--> |BDD|----->| GEN |-->( SRC )-->| compilateur |-->( EXE )
/______| -------- |___| ------- (_____) --------------- (_____)
Aussi bien pour les programmes de mise ŕ jour de la base de données de programmation (MAJ) que pour les programmes générés par l'AGL (EXE) : imaginez un formulaire HTML, en police ŕ espacement fixe, limité ŕ 24 lignes et 80 colonnes, avec uniquement des champs "Textentry".
Nous avions ainsi l'élégance graphique de curses avec la puissance ergonomique de textentry HTML (en web 1.0).
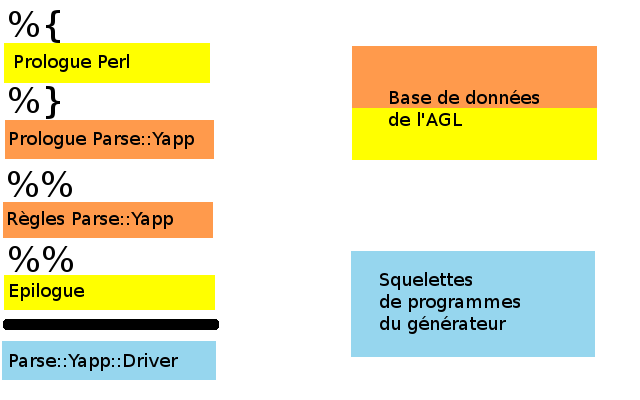
Un programme de génération lit la base de données et génčre le source COBOL du programme applicatif demandé. C'est un peu semblable ŕ yacc, bison ou Parse::Yapp :
Une partie du source généré provient quasiment sans modification des enregistrements de la table "lignes de programme" de la base de données. Ŕ la différence de Parse::Yapp, il y a quand męme une légčre adaptation des sources pour transformer par exemple la ligne
MP ZONE1 ZONE2
en
MULTIPLY ZONE1 BY ZONE2
(ah les délices de la verbosité COBOL !) mais il n'y a aucune peine ŕ deviner le source COBOL correspondant. Elle est représentée en jaune dans le schéma.
Une partie du source généré provient des enregistrements des autres tables pour le programme ŕ générer : table des appels de structures de données, table de description des grilles-écrans, etc. Les enregistrements sont malaxés, pétris et triturés pour en sortir du COBOL. Elle est représentée en orange dans le schéma.
Une derničre partie est indépendante du programme généré. On la retrouve identique dans tous les programmes IBM-CICS, on retrouve une autre version dans tous les programmes Bull-GCOS7, une troisičme version dans tous les programmes Unisys, et ainsi de suite. Par exemple, l'appel systčme chargé de récupérer la date et l'heure courantes. Pour Parse::Yapp, cela correspond au code écrit par François Désarménien ou ses successeurs et inclus directement dans le module objet. Cette partie est représentée en bleu dans le schéma.
___
( ) Squelette
_____ ___ (___) de programme
|( )| (___) | _____ _____
|( )| -------- | | -->------- ( ) --------------- ( )
------| <-->| MAJ |<--> |BDD|----->| GEN |-->( SRC )-->| compilateur |-->( EXE )
/______| -------- |___| ------- (_____) --------------- (_____)
Dans le schéma ci-dessus, les fichiers marqués SRC contiennent le source COBOL des programmes. En principe, ce sont des fichiers temporaires. S'il y a une erreur ŕ la compilation, c'est dans la base de données qu'il faut corriger l'erreur.
Rappelons que La Boîte a deux activités : services et éditeur de logiciels (dont l'AGL). Dans le schéma ci-dessus, les squelettes de programme (en bleu) sont écrits par les personnes de l'activité édition de logiciel. Certains programmeurs de ce département connaissent trčs bien la programmation en COBOL IBM-CICS, d'autres sont experts en programmation COBOL BULL-GCOS7, d'autres encore en COBOL BULL-GCOS8, mais aucun d'entre eux ne sait gérer des stocks, créer des factures ou construire un bulletin de paie (enfin, certains, si, mais ce n'est pas ce qu'on leur demande dans leur poste actuel).
D'un autre côté, la base de l'AGL (en jaune et orange) est alimentée par les programmeurs de l'activité services. Ils ne connaissent pas les arcanes de la programmation en COBOL IBM-CICS ou en COBOL BULL-GCOS7, mais ils savent comment gérer des stocks, créer des factures et construire un bulletin de paie. Ces programmeurs peuvent acquérir sur le tas quelques notions relevant des arcanes de la programmation COBOL IBM-CICS, par exemple, mais ce n'est pas indispensable, on leur demande surtout de connaître les bases de la programmation et de comprendre le contexte fonctionnel du projet : stocks, gestion du personnel, etc., selon le cas.
Pour revenir aux programmeurs de l'activité édition de logiciels, s'ils sont capables de programmer en COBOL en tapant directement dans un éditeur de source, ils utilisent quand męme l'AGL. Cela va plus vite pour écrire les programmes, notamment pour maquetter les grilles d'écran. Ainsi donc, comme nombre d'outils logiciels, l'AGL est bootstrapé : l'AGL 7.2 alpha est écrit en AGL 7.1, l'AGL 7.2 RC1 est écrit en AGL 7.2 alpha, l'AGL 7.2 définitif est écrit en AGL 7.2 RC1. Les programmeurs de l'activité édition de logiciels sont donc eux-męmes des utilisateurs de l'AGL, mais avec un contexte fonctionnel trčs différent. Donc, en fait, les programmeurs de l'activité édition de logiciel tapent ŕ la fois dans les fichiers en bleu et dans la base de données en jaune + orange.
La description de COBOL est trčs partielle, pour plusieurs raisons. Tout d'abord, je ne vous livre que ce qui est indispensable pour comprendre l'anecdote de janvier 1988.
D'autre part, l'AGL étant censé fonctionner sur de nombreuses architectures différentes, le COBOL enseigné aux programmeurs de l'activité services (dont moi), ne comportait que les éléments communs ŕ toutes les architectures.
Finalement, souvenez-vous que je présente l'état de l'art des années 1986 ŕ 1988. Ŕ cette époque, męme des architectures plus évoluées comme Unix ne disposaient pas de fonctionnalités que nous tenons pour acquises en 2013. Ainsi, pas d'Unicode. Déjŕ que le support des jeux de caractčres ISO-8859 (ou leur équivalent sur les architectures EBCDIC) n'était pas toujours trčs bien assuré par tous les logiciels, alors ne parlons pas d'Unicode. Également, la programmation orientée objet commençait ŕ poindre avec C++, Smalltalk et quelques autres langages tout aussi exotiques, mais ce concept n'avait pas encore atteint la communauté COBOL (et lorsqu'il l'a atteint quelques années plus tard, c'était ŕ mon avis plus du buzz perçu comme tel par les programmeurs qu'une réelle révolution de la programmation COBOL).
Donc je vous présente uniquement la façon de définir les données. Pour les instructions de programmation, j'utiliserai du pseudo-code avec la syntaxe de Perl.
La façon d'interagir avec les données du programme est trčs différente pour un programmeur Perl et un programmeur COBOL, surtout un programmeur qui utilise l'AGL.
Le nom d'une variable COBOL peut contenir des lettres, des chiffres, mais aussi des tirets. Il me semble que l'utilisation du blanc souligné doit ętre possible mais les programmeurs COBOL ont l'habitude du tiret. De plus, il est tout-ŕ-fait légal de faire commencer un nom de variable par un chiffre.
Pas de rčgle de visibilité ni de durée de vie : dans un programme COBOL, toutes les variables sont visibles de tout point du programme, elles existent toutes lorsque le programme démarre et elles perdurent jusqu'ŕ l'arręt du programme. Aucune création dynamique en COBOL.
Un programmeur Perl se fiche de savoir quelle est la représentation
hexadécimale de sa variable. Y compris lorsqu'il interagit avec
une base de données. La seule fois qu'il peut s'y intéresser, c'est lors
de l'utilisation d'un pack ou d'un unpack. Pour un programmeur
COBOL, il est naturel de savoir comment quelle est la représentation
hexadécimale de chaque variable de son programme.
Lorsque l'on alimente une variable alphanumérique avec une valeur trop courte, elle est complétée avec des blancs ŕ droite. Lorsque la valeur est trop longue pour la variable réceptrice, elle est tronquée.
Un programmeur Perl ne préoccupe pas de savoir comment les variables sont organisées en mémoire. Il n'a aucune notion de succession ou de voisinage. Un programmeur COBOL sait comment ses variables sont agencées en mémoire.
Les tableaux COBOL sont indicés ŕ partir de 1 et leur taille est fixe (en général). Tout accčs utilisant un indice incorrect fait planter le programme. Pas de buffer overflow, pas d'agrandissement implicite du tableau.
Données numériques
Pour rester simple, je vous épargne des détails inutiles comme la représentation des données signées ou des nombres ŕ virgule fixe ou ŕ virgule flottante. En revanche, il est nécessaire de parler de la classe de stockage.
Il y a le décimal étendu (DISPLAY), le décimal codé binaire ou décimal condensé (COMP-3) et le binaire (COMP-4 ou COMPUTATIONAL). En décimal étendu, chaque chiffre correspond ŕ un octet. On peut avoir quelques fonctionnalités avancées de présentation, comme le remplacement des zéros de tęte par des espaces. En décimal condensé, chaque chiffre est stocké dans la moitié d'un octet ; les chiffres hexadécimaux de "A" ŕ "F" ne sont pas utilisés, sauf sur certaines machines oů l'on trouve un "F" pour notifier qu'il s'agit d'un nombre non signé. Quant ŕ la classe binaire, je n'ai pas besoin d'entrer dans les détails.
Exprimons 12345 dans les divers formats :
9(8) DISPLAY F0F0F0F1F2F3F4F5 ou "00012345"
3030303132333435 sur une machine ASCII
Z(7)9 DISPLAY 404040F1F2F3F4F5 ou " 12345"
2020203132333435 sur une machine ASCII
9(8) COMP-3 00012345 sur certaines architectures
000012345F sur d'autres
9(8) COMP-4 00003039
Exemple de structure de données :
01 DONNEES.
05 K01A.
10 K01 PIC 9(4) COMPUTATIONAL.
05 TABJOU-INIT PIC X(36)
VALUE "031059090120151181212243273204334365".
05 TABJOU-T REDEFINES TABJOU-INIT.
10 TABJOU PIC 999 DISPLAY
OCCURS 12.
En rčgle générale, l'agencement des données est contrôlé par un systčme de niveaux hiérarchiques. Une variable de niveau hiérarchique 01 s'étend jusqu'ŕ la variable suivante de niveau 01 et elle groupe ainsi toutes les variables de niveau hiérarchiquement inférieur (c'est-ŕ-dire numériquement supérieur). De la męme maničre, une variable de niveau 05 s'étend jusqu'au niveau 05 (ou hiérachiquement supérieur, numériquement inférieur) suivant.
Si une variable est suivie par une variable de niveau inférieur, la premičre variable est une « zone groupe » regroupant toutes les variables qui suivent, jusqu'ŕ la variable de niveau supérieur ou égal. Ainsi, ci-dessus, la variable K01A est une zone groupe contenant la variable K01, tout comme la variable DONNEES est une zone groupe contenant K01A, K01, TABJOU-INIT, TABJOU-T et TABJOU.
Une zone groupe est obligatoirement une zone alphanumérique. Sa longueur est calculée en additionnant la longueur en octets des zones élémentaires qui la composent.
Cas particulier : si une variable est qualifiée avec
un REDEFINES, elle n'est pas collée ŕ la suite de
la variable précédente de męme niveau, mais elle lui
est superposée. Les deux zones doivent avoir la męme
longueur et cette longueur est comptée une seule fois
pour calculer la longueur de la zone englobante.
L'une des utilisations de REDEFINES est, comme ci-dessus,
l'initialisation du contenu d'un tableau. L'équivalent
en Perl serait :
my @tabjou = (31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 335, 365);
Dans les années 1960, la mémoire de masse et surtout la mémoire vive coűtaient trčs cher. Pour stocker une date, on utilisait une année ŕ deux chiffres. Dans le contexte de l'époque, c'était parfaitement justifié.
Quand l'AGL est sorti, il proposait plusieurs formats de date :
Le format interne, AAMMJJ, utile pour les index de base de données et les tris.
Le format d'entrée JJMMAA, pour les champs saisissables dans les grilles d'écran et éventuellement pour les interfaces avec d'autres systčmes.
Le format de sortie JJ/MM/AA pour les champs affichés et pour les éditions sur papier.
En plus de ces formats, l'AGL fournissait des macro-instructions permettant de passer de l'un ŕ l'autre.
Remarque : lors de l'installation de l'AGL, on pouvait spécifier un paramčtre pour indiquer que l'on préférait utiliser les dates MMJJAA plutôt que JJMMAA. Il me semble que le choix était définitif. Une fois l'installation effectuée, plus moyen de changer. Dans la suite du texte, je ne m'intéresse plus ŕ cette problématique, je ne considčre que les dates JJMMAA ou similaires.
Au cours des années 1970, les banques ont commencé ŕ utiliser des années ŕ 4 chiffres, pour les pręts ŕ long terme. En revanche, pour les autres applications, on continuait ŕ utiliser des années ŕ 2 chiffres. En l'absence de pression du marché, l'AGL a continué ŕ utiliser des années ŕ 2 chiffres.
En 1986, lors de la sortie de la version 7.2, l'AGL a proposé des formats de date avec une année ŕ 4 chiffres : le format interne étendu AAAAMMJJ, le format d'entrée étendu JJMMAAAA et le format de sortie étendu JJ/MM/AAAA. Les anciens formats sont toujours disponibles pour la compatibilité ascendante.
Je ne me souviens plus s'il était possible de copier une date avec un format court dans une date avec un format long. Mais si c'était possible, la conversion AA -> AAAA se faisait en collant "19" sans plus se poser de question. On était seulement en 1986 aprčs tout, il y aurait d'autres versions de l'AGL avant que le problčme se pose.
De fait, vers 1995, peut-ętre avant, une nouvelle version permet de préciser comment s'effectue la conversion AA -> AAAA. En fonction d'un paramčtre d'installation, alimenté par exemple ŕ la valeur "80", toutes les années AA > 80 sont converties en "19AA" et toutes les années <= 80 sont converties en "20AA".
Premier janvier 2000 : les désastres annoncés ne se sont pas réalisés. Il y a eu des problčmes sur des programmes COBOL, mais aussi des programmes C, C++, Java, Perl, Python, mais les victimes ont préféré ne rien dire pour ne pas perdre la face.
Mais revenons ŕ la version 7.2 en 1986.
Ŕ chaque changement de version de l'AGL, c'était la variante IBM-CICS qui sortait la premičre : la majorité des clients utilisaient cette variante, donc le retour sur investissement pour La Boîte était plus rapide.
Si l'AGL 7.2 commençait ŕ prendre de bonnes habitudes avec les formats de date et les années ŕ 4 chiffres, ce n'était pas encore le cas pour IBM-CICS. La date systčme n'était męme pas fournie au format AAMMJJ, mais au format AAQQQ.
86001 -> 1er janvier 1986 86365 -> 31 décembre 1986 88365 -> 30 décembre 1988 88366 -> 31 décembre 1988
Il n'y a que les programmeurs chez IBM pour aimer le format AAQQQ. Pour la santé mentale des autres, l'AGL fournissait une routine de conversion que je vous présente ci-dessous.
Voici donc ci-dessous le traitement de la date systčme dans un programme IBM-CICS, en décrivant les données en COBOL mais en donnant les instructions exécutables en pseudo-code Perl sur la partie droite de la page. Dans la réalité, c'était du COBOL situé plusieurs pages plus bas.
Voici la premičre version. Ne faisant pas partie de l'équipe développant l'AGL, je n'ai pas connu cette version, ni les suivantes. Je n'ai connu que la derničre. Les premičres versions présentées, ainsi que le processus de développement, sont donc des reconstitutions.
01 DONNEES.
05 K01A.
10 K01 PIC 99 DISPLAY.
05 TABJOU-INIT PIC X(36)
VALUE "031059090120151181212243273204334365". $dat5 = qx(sysdate);
05 TABJOU-T REDEFINES TABJOU-INIT. $datoaa = $dat51;
10 TABJOU PIC 999 DISPLAY $datoj = $dat52;
OCCURS 12. $k01a = 0;
05 DAT5. debut:
10 DAT51 PIC 99 DISPLAY. $k01++;
10 DAT52 PIC 999 DISPLAY. if ($dat52 <= $tabjou[$k01]) {
05 DATOR. goto fin;
10 DATOA. }
15 DATCE PIC 99 DISPLAY VALUE "19". $datoj = $dat52 - $tabjou[$k01];
15 DATOAA PIC 99 DISPLAY. goto $debut;
10 DATOM PIC 99 DISPLAY. fin:
10 DATOJ PIC 99 DISPLAY. $datom = $k01;
On relit le traitement, on regarde ce qui se passe avec 86001 (1er janvier), avec 86031 (31 janvier), avec 86032 (1er février), avec 86335 (1er décembre) et avec 86365 (31 décembre). Ça marche. Donc on complčte l'algorithme :
01 DONNEES. $dat5 = qx(sysdate);
05 K01A. $datoaa = $dat51;
10 K01 PIC 99 DISPLAY. if ($dat51 % 4 == 0) {
05 TABJOU-INIT PIC X(36) goto bissextile;
VALUE "031059090120151181212243273204334365". }
05 TABJOU-T REDEFINES TABJOU-INIT. $datoj = $dat52;
10 TABJOU PIC 999 DISPLAY $k01a = 0;
OCCURS 12. debut:
05 TABBIS-INIT PIC X(36) $k01++;
VALUE "031060091121152182213244274205335366". if ($dat52 <= $tabjou[$k01]) {
05 TABBIS-T REDEFINES TABBIS-INIT. goto fin;
10 TABBIS PIC 999 DISPLAY }
OCCURS 12. $datoj = $dat52 - $tabjou[$k01];
05 DAT5. goto debut;
10 DAT51 PIC 99 DISPLAY. bissextile:
10 DAT52 PIC 999 DISPLAY. $datoj = $dat52;
05 DATOR. $k01a = 0;
10 DATOA. debutbis:
15 DATCE PIC 99 DISPLAY VALUE "19". $k01++;
15 DATOAA PIC 99 DISPLAY. if ($dat52 <= $tabbis[$k01]) {
10 DATOM PIC 99 DISPLAY. goto fin;
10 DATOJ PIC 99 DISPLAY. }
$datoj = $dat52 - $tabbis[$k01];
goto debutbis;
fin:
$datom = $k01;
Nouvelle phase de relecture. Certes, il y aura un problčme lorsque l'on atteindra l'année 2100, qui sera considérée ŕ tort comme une année bissextile. Et il y aura un problčme en 2000, qui sera transcrit en 1900. Mais on n'en est pas encore lŕ, il y aura une nouvelle version, pour corriger.
On compile, on teste... et ça marche !
Mais quelqu'un remarque que l'on utilise un champ numérique DISPLAY pour indicer un tableau. Ce n'est pas performant, cela gaspille quelques nanosecondes ŕ chaque exécution, ce n'est pas bien. D'oů correction.
01 DONNEES. $dat5 = qx(sysdate);
05 K01A. $datoaa = $dat51;
10 K01 PIC 9(4) COMPUTATIONAL. if ($dat51 % 4 == 0) {
05 TABJOU-INIT PIC X(36) goto bissextile;
VALUE '031059090120151181212243273204334365'. }
05 TABJOU-T REDEFINES TABJOU-INIT. $datoj = $dat52;
10 TABJOU PIC 999 DISPLAY $k01a = 0;
OCCURS 12. debut:
05 TABBIS-INIT PIC X(36) $k01++;
VALUE '031060091121152182213244274205335366'. if ($dat52 <= $tabjou[$k01]) {
05 TABBIS-T REDEFINES TABBIS-INIT. goto fin;
10 TABBIS PIC 999 DISPLAY }
OCCURS 12. $datoj = $dat52 - $tabjou[$k01];
05 DAT5. goto $debut;
10 DAT51 PIC 99 DISPLAY. bissextile:
10 DAT52 PIC 999 DISPLAY. $datoj = $dat52;
05 DATOR. $k01a = 0;
10 DATOA. debutbis:
15 DATCE PIC 99 DISPLAY VALUE '19'. $k01++;
15 DATOAA PIC 99 DISPLAY. if ($dat52 <= $tabbis[$k01]) {
10 DATOM PIC 99 DISPLAY. goto fin;
10 DATOJ PIC 99 DISPLAY. }
$datoj = $dat52 - $tabbis[$k01];
goto debutbis;
fin:
$datom = $k01;
On compile, on teste... et ça plante !
Pourquoi ? Parce que l'initialisation de l'indice K01 est mauvaise. On met du ZERO dans la variable groupe, donc dans de l'alphanumérique. Cela remplit donc chaque octet avec un caractčre "0". Tant que le champ numérique sous-jacent était du numérique DISPLAY, cela collait, la conversion se faisait sans problčme. Mais maintenant que c'est du COMPUTATIONAL, cela équivaut ŕ initialiser le champ ŕ 0xF0F0 (en EBCDIC), donc 61680. Et l'accčs au tableau plante en débordement d'indice, cet indice valant 61681.
On corrige.
01 DONNEES. $dat5 = qx(sysdate);
05 K01A. $datoaa = $dat51;
10 K01 PIC 9(4) COMPUTATIONAL. if ($dat51 % 4 == 0) {
05 TABJOU-INIT PIC X(36) goto bissextile;
VALUE '031059090120151181212243273204334365'. }
05 TABJOU-T REDEFINES TABJOU-INIT. $datoj = $dat52;
10 TABJOU PIC 999 DISPLAY $k01 = 0; # Ne pas initialiser la zone groupe $k01a !
OCCURS 12. debut:
05 TABBIS-INIT PIC X(36) $k01++;
VALUE '031060091121152182213244274205335366'. if ($dat52 <= $tabjou[$k01]) {
05 TABBIS-T REDEFINES TABBIS-INIT. goto fin;
10 TABBIS PIC 999 DISPLAY }
OCCURS 12. $datoj = $dat52 - $tabjou[$k01];
05 DAT5. goto $debut;
10 DAT51 PIC 99 DISPLAY. bissextile:
10 DAT52 PIC 999 DISPLAY. $datoj = $dat52;
05 DATOR. $k01a = 0;
10 DATOA. debutbis:
15 DATCE PIC 99 DISPLAY VALUE '19'. $k01++;
15 DATOAA PIC 99 DISPLAY. if ($dat52 <= $tabbis[$k01]) {
10 DATOM PIC 99 DISPLAY. goto fin;
10 DATOJ PIC 99 DISPLAY. }
$datoj = $dat52 - $tabbis[$k01];
goto debutbis;
fin:
$datom = $k01;
On compile, on teste, ça fonctionne. Ouf ! Donc on livre. Et tout au long de l'année 1987, les clients utilisant IBM-CICS ont installé l'AGL 7.2 et ont recompilé leurs programmes.
Puis arrive 1988 (lŕ encore, c'est une reconstitution de la façon probable dont les événements se sont déroulés). Le premier janvier est un vendredi, donc le premier jour ouvré est le lundi 4 janvier 1988. Dans chaque site équipé en AGL 7.2, les utilisateurs les plus matinaux arrivent, prennent un café, souhaitent la bonne année ŕ ceux qui arrivent 5 ou 10 minutes aprčs eux, reviennent ŕ leur bureau, allument leur terminal, se connectent ŕ leur application et... ça plante ! En fait, dans le cas de mon ancien client, ça plante sur la moitié des applications, l'autre moitié fonctionne bien. On s'aperçoit rapidement que cela plante sur les applications développées avec l'AGL (stocks, suivi de la main d'œuvre, données techniques des bureaux d'étude) et que cela fonctionne sur les progiciels développés par les concurrents de La Boîte (compta, paie, gestion de production). Mais je vous laisse imaginer l'ambiance chez d'autres clients, qui auraient pu choisir de tout développer en spécifique avec l'AGL...
Pourquoi le plantage ? Remontons dans le source livré.
L'initialisation de K01A / K01 a été corrigée dans la
moitié traitant les années normales, mais elle a été laissée
dans la moitié traitant les années bissextiles.
Donc TOUS les programmes recompilés depuis l'installation
de l'AGL 7.2 plantent.
La premičre réaction qui vient ŕ l'esprit est de se connecter ŕ l'AGL pour relancer la compilation des programmes. Or, comme je l'ai déjŕ expliqué, l'AGL est développé avec lui-męme. Donc, dans ce cas, les programmes interactifs de l'AGL présentent le męme bug ! Impossible de se connecter ŕ l'AGL pour lancer une génération !
Heureusement, les programmes de génération sont des programmes batchs. Ils n'utilisent pas le squelette IBM-CICS, et ne sont donc pas bugués. Seul le programme permettant de lancer une génération est un programme interactif CICS mais il est possible de lancer des générations sans passer par ce programme interactif. En écrivant un fichier en JCL (un langage encore plus désagréable que Cobol et CICS réunis, il n'y a que les programmeurs chez IBM pour aimer le JCL), on peut lancer la génération de quelques programmes. En adaptant le JCL, on peut męme conserver les sources COBOL dans des fichiers permanents. Ensuite, il faut corriger la ligne erronée avec un éditeur de texte (impossible d'automatiser cette étape, pas de "sed", pas de "awk" et pas de Perl sur une machine MVS). Puis, lancer la compilation. Enfin, de temps en temps, compacter la bibliothčque de programmes exécutables, ce qui, soit dit en passant, ne peut se faire que si CICS est arręté, c'est-ŕ-dire en empęchant de travailler ceux qui avaient la possibilité d'utiliser un progiciel indépendant de l'AGL (compta, paie, GP chez mon ancien client).
Męme si le problčme a été rapidement détecté, identifié et corrigé par l'équipe "édition de logiciels" de La Boîte, il a fallu livrer les programmes corrigés de l'AGL ŕ mon ancien client et ŕ tous les autres qui utilisaient l'AGL 7.2 pour IBM-CICS. Męme si, ŕ l'époque, il existait déjŕ dans les facs et les labos de recherche un truc appelé Arpanet, ou Internet, ou FTP, męme si ŕ l'époque, les particuliers français surfaient sur "3615 ULLA" ou "3615 LAREDOUTE", mais cela concernait surtout les loisirs et la vente par correspondance, pas l'industrie en tant que telle. Quant aux entreprises en général, certaines utilisaient des liaisons spécialisées pour faire communiquer des sites éloignés, d'autres, rares, étaient abonnées ŕ Transpac ou ŕ un réseau similaire, mais la plupart du temps, les entreprises n'avaient pas de communication informatique avec l'extérieur. La diffusion des logiciels se faisait trčs souvent par un programmeur ou un coursier qui se déplaçait chez le client avec une bande magnétique sous le bras (cela m'est arrivé ŕ d'autres occasions) ou dans le coffre de sa voiture. Imaginez donc qu'il a fallu faire cela des centaines de fois pendant les premiers jours de janvier !
Je n'ai pas vécu cet événement personnellement, j'étais tranquille chez mon client Sperry-Unisys-AGL 7.1. Ce n'est que quelques mois plus tard que, lors d'une brčve conversation, j'ai eu vent d'un problčme qui avait affecté tous les sites CICS-AGL 7.2. Comme j'avais gardé des listings COBOL de programmes développés chez mon premier client, j'ai pu reconstituer le bug. Hélas, j'ai bazardé ces listings quelques années plus tard et j'ai été obligé de reconstituer de mémoire la portion de code incriminée. Ŕ part cette brčve conversation et ces listings perdus, je n'ai jamais eu vent de ce problčme. C'était un cadavre enfermé dans un placard verrouillé avec des cadenas dont on a pris grand soin d'égarer la clé. Męme en consultant le forum sur les risques technologiques ŕ la date de janvier-février 1988, je n'ai rien trouvé.
En fait, on pourrait dire que l'AGL 7.2 avait 12 ans d'avance et que l'on a connu le bug Y2K en janvier 1988 au lieu de janvier 2000. Il y a de nombreuses ressemblances entre janvier 1998 et ce qu'on nous annonçait pour janvier 2000 :
bug dű ŕ l'utilisation d'années tantôt ŕ 2 chiffres, tantôt ŕ 4 chiffres,
bug se produisant début janvier,
blocage presque complet,
y compris des moyens de correction,
et silence complet une fois que c'est arrivé.
Quant ŕ vous qui utilisez Perl, utilisez Devel::Cover et essayez autant que possible d'avoir une couverture de code complčte.
En réfléchissant de nouveau ŕ cette anecdote dont je n'ai pas été le témoin direct, je pense que le déroulement a pu ętre assez différent. Le problčme aurait été détecté en aoűt ou septembre 1987, une version 7.2a aurait été diffusée dans la foulée, tous les clients CICS / AGL-7.2 sauf 2 ou 3 auraient recompilé tous leurs programmes en novembre et décembre 1987, sans confondre vitesse et précipitation et tous, sauf les deux ou trois évoqués, auraient eu un mois de janvier 1988 paisible. Ensuite, mon collčgue aurait eu vent des problčmes de l'un de ces trois clients imprévoyants et procrastinateurs et aurait "amélioré" l'histoire en prétendant que tous les clients CICS / AGL-7.2 ont été touchés.
Cela expliquerait pourquoi il n'y a aucune trace de cet événement somme toute mineur dans le Forum sur les Risques technologiques et dans Wikipedia. D'autre part, ce n'est plus un avant-goűt de la catastrophe annoncée par les media ŕ sensations pour le premier janvier 2000, c'est plutôt un avant-goűt de ce qui s'est réellement produit : la plupart des gens concernés ont su prendre ŕ temps les bonnes mesures pour éviter la catastrophe et les rares personnes affectées ont balayé l'incident sous le tapis pour éviter de perdre la face.
Quoi qu'il en soit, la morale de l'histoire est que męme si ce n'est pas une panacée, s'assurer d'une bonne couverture du code est bénéfique pour vos projets.